Todd's Blog
Publications
Presentations
Events
My Book: Stand
Back & Deliver
Fun Stuff
Contact
Home
Todd Little
It's all about making ship happen.
Featured Content
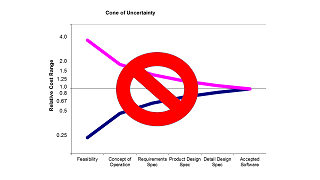
Estimation, #NoEstimates and the Cone of Uncertainty
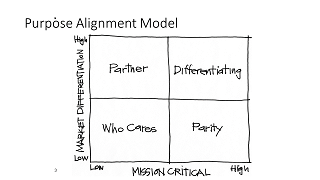
Product Strategy
Context Leadership
Antipatterns
General Leadership
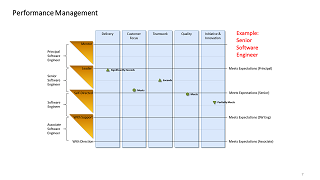
(Performance Management)
Distributed and Offshore
Simulations and Games
About Todd
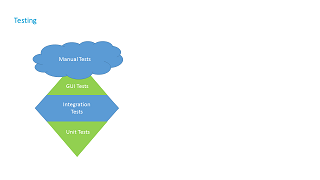
Testing
Todd Little
todd@toddlittleweb.com